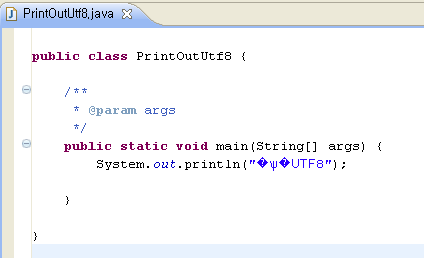
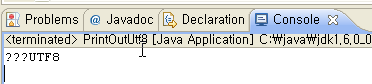
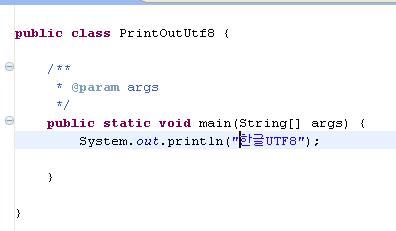
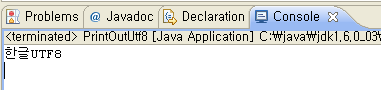
Exception in thread "main" java.sql.SQLException: Incorrect string value: '\xEB\xB0\xB1\xEA\xB8\xB0...' for column 'name' at row 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1055)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:956)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3515)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3447)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1951)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2101)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2554)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1761)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:2046)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1964)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1949)
at springbook.user.dao.UserDao.add(UserDao.java:23)
at springbook.user.dao.UserDao.main(UserDao.java:60)
Class.forName("com.mysql.jdbc.Driver");
Connection c = DriverManager.getConnection("jdbc:mysql://localhost/springbook?characterEncoding=UTF-8", "spring","book");
create table users (
id varchar(10) primary key,
name longtext not null,
password varchar(10) not null
) DEFAULT CHARSET=utf8;
![초급자를 위해 준비한 인프런 [데브옵스 · 인프라] 강의](https://okdevtv.com/images/inflearn-react-api.webp)