웹이 보편화되면서 브라우저에서의 문자세트에 대한 얘기도 점점 많아지고 있습니다. 글자가 깨져 보이는 경우는 바로 이 문자세트가 맞지 않아서인데, 세상의 모든 언어들을 한 화면에 표시하기 위한 방식이 UTF8입니다. 물론 포토샵 등으로 이미지를 통해서 한 화면에 표시하는 방법도 있기는 하죠. 철푸덕. ^^;
동일한 내용의 파일이 문자세트에 따라 어떤 차이가 있는지 간략히 살펴보겠습니다.
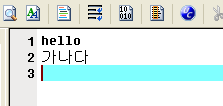
text
필자가 좋아하는 에디터인 울트라에디트를 이용해서 적어놓은 글자들입니다. ctrl+H를 하면 16진수 형태의 코드로 보여지는데 다음과 같습니다.

ANSI charset
컴퓨터가 내부적으로 기억하는 코드를 볼 수 있습니다. h에 해당하는 68은 16진수로 표기된 것이고 10진수로 바꾸면 6*16+8 = 96+8 = 104 입니다. 104번째 해당하는 문자라는 것을 알 수 있죠. 0D 0A 부분이 보일 텐데, windows에서 엔터를 치면 이렇게 두 문자(2 bytes)가 자동으로 만들어집니다. java에서 "\r\n" 이라고 하는 표시하는 것과 일맥상통하죠. 뒤 이어 한글은 두 자리로 되어있는데, "가"는 B0 A1, "나"는 B3 AA 로 컴퓨터가 기억하고 있다는 것을 알 수 있습니다.
울트라에디트에서 이것을 utf8로 변환해보겠습니다. 다시 ctrl+H를 눌러서 일반텍스트 편집화면으로 되돌립니다.
메뉴의 파일(
F)에서 "변환"을 선택하고 ASCII -> UTF8(Unicode 편집) 항목을 선택합니다.
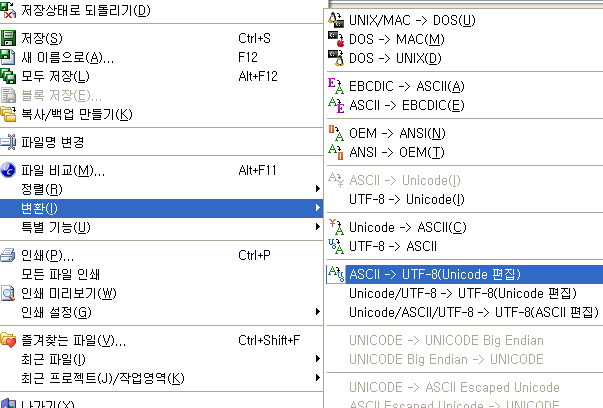
conversion
파일의 코드셋이 변경되었습니다. 다른 이름으로 저장해보겠습니다.
파일의 크기가 바뀐 것을 감지하셨는지 모르겠네요. ^^; hello_utf8.txt로 저장을 했는데 이 파일을 열어서 ctrl+H를 해보면 다음과 같습니다.

utf8 hex view
h앞에 세 문자가 더 들어간 것을 볼 수 있습니다. "EF BB BF". 그리고 영어부분은 이전과 같은데 한글부분의 문자가 2바이트 단위에서 3바이트 단위로 늘어났습니다. 즉 "가"가 EA BO 80 이고 "나"가 EB 82 98 입니다.
정리를 하자면 같은 내용의 문자열을 표시한다고 해도 문자세트(코드세트, charset)에 따라서 내부적으로 기억하는 방식은 다르다는 것입니다.
한 가지 더, utf8편집을 위해서 ultraedit 만 필요한 것은 아닙니다. windows의 메모장에서도 편집이 가능합니다. 저장할 때 파일명을 적고 아래에 있는 인코딩을 ANSI에서 UTF-8로 정해주면 됩니다.
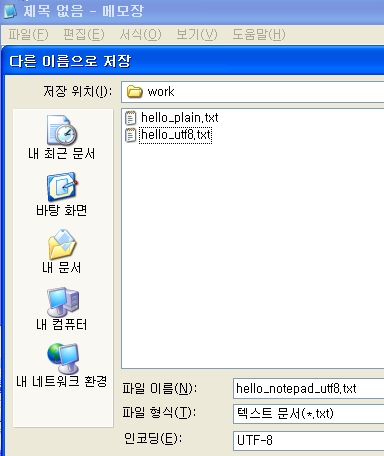
메모장 utf8
아, Mac에서는 Smultron (
http://smultron.sourceforge.net/)이라는 편집기를 사용하고 있습니다.
읽어주셔서 감사합니다. ^^



![초급자를 위해 준비한 인프런 [데브옵스 · 인프라] 강의](https://okdevtv.com/images/inflearn-react-api.webp)